
- The Simulator
- Deep Q-Learning Setup
- My First Deep Q-Net
- Q-Net Architecture
- Iteration 1: Learning To Do Nothing
- Iteration 2: Static Obstacle Avoidance
- Iteration 3: Static And Random
- ToDo - Iteration 4: Dynamic And Random 2 Obstacles
- ToDo - Iteration 5: Dynamic And Random 0–10 Obstacles
- Looking To The Future
2021: A bit of a caveat. This was the first project (other than Mnist) that I tried to apply Deep Learning to. Back when I was in the; “Just through some Deep Learning and 🤖 bleep bloop, how hard could it be?” Phase of my ML journey. (Spoiler, it didn’t work).
Recently, I was fortunate enough to be awarded a Data61 summer research scholarship from the CSIRO. This post is the second of a 3 part series detailing what I learned, the conclusions I came to and some mistakes I made along the way. My chosen topic was Deep Q-Learning For Self-Driving Cars.
This installment outlines my implementation of Deep Q-Learning to navigate a straight stretch of simulated highway. The end goal of the project is to train a model well enough to control an RC Car, then, if all goes well, something larger. This project does not aim to train an end-to-end self-driving car using deep reinforcement learning. The idea is that the car (agent) is travelling along a predefined path but the Q-Net needs to intervene in order to avoid unforeseen obstacles.
If you are unfamiliar with Deep Q-Learning. I would also highly recommend reading my previous post, “Introduction to Deep Q-Learning”. For additional material:
- This was the first tutorial I read on Q-Learning and Deep Q-Learning. It is an easy to follow walk trough with clear concise code. Thanks Brandon
- A more in depth concepts including Double Deep Q-Neural Network and Dueling Deep Q-Neural Networks these are great!!! Thanks Arthur
- If you’re not really familiar with TensorFlowis there online documentation. If they are not doing it for you.
- Hvass-Labs has a great tutorial series on git that helped got me started. Thanks Magnus
The Simulator
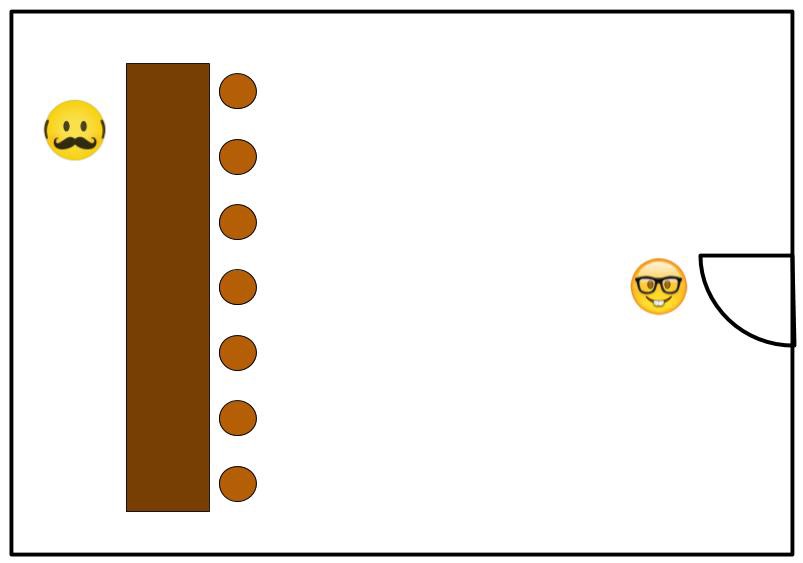
The sim consist of an agent (red) and obstacles (grey). Depending on the settings the obstacles can be stationary or moving. They can be initialized in random or predetermined positions and merge with a certain probability. The agent is equipped with a simulated LiDAR that returns an array of distance measurements to any object a beam hits. The environment is a 6 lane highway with 3 lanes in both directions. There is also a shoulder the car cannot drive on. As with many highways, adjacent the shoulder are barriers the LiDAR can also detect. The red circle is an approximate bounding box for collision detection. The little orange circle is the PID target (carrot) followed by the agent. Each frame the carrot is kept a set distance from the agent, the agent uses PID to chase the carrot *across the screen. To *veer_left or veer_right, the *carrot *is incremented up or down the screen.
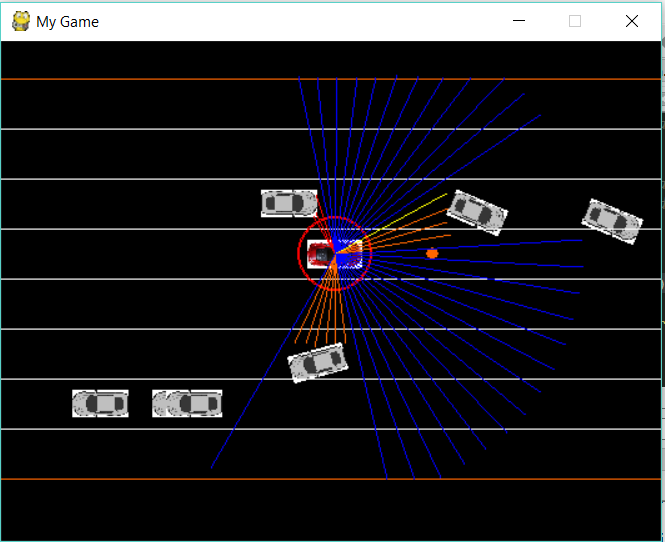
Screen shot of the PyGame Simulator. The red car is agent, it is the goal of the agent to place the orange dot in one of the lanes, the car is programmed to track the dot with a simple PID loop. The lines fanning out infront of the car are simulating LiDAR beams. The colour of the LiDAR lines indicates how close another car is. Finally the gray cars are TERRIBLE drivers, programmed to randomly change lanes with zero regard for agent's wellbeing
Each iteration the agent can take 1 of 5 actions.
- accelerate: increase speed by ENV_PARAMS.CAR_ACCELERATION
- break: decrease speed by ENV_PARAMS.CAR_ACCELERATION
- veer_left: decreases PID target (carrot) Y-position by ENV_PARAMS.CARROT_INCREMENT
- veer_right: increases carrot Y-position by ENV_PARAMS.CARROT_INCREMENT
- do_nothing: follows current carrot
In order to get a feel for the relative motion of the obstacles, 4 frames of LiDAR data is combined into one array that can be seen below. Each row of the array represents a single LiDAR beam. The columns represent the distance reading returned by a particular beam. The most recent beam is given the value 1 followed by 0.5, 0.25 and 0.125 as the scans get older. If overlapping occurs the elements are added.
Deep Q-Learning Setup
This implementation of Deep Q-Learning is epsilon greedy, initially epsilon is set to 0.9 and is decreased by 1/100,000 each frame. An experience replay buffer of 100,000 frames is used with a batch size of 30. We loop until the maximum future reward predicted by the Q-Net converges. The convergence of the future reward was suggested in Mnih et al) as a more stable option than the loss functions.
The reward system went through several iterations. Initially, my idea was to have the agent account for various levels of urgency. I devised a simple proximity based penalty system with negative rewards increasing as obstacles became closer to the agent.
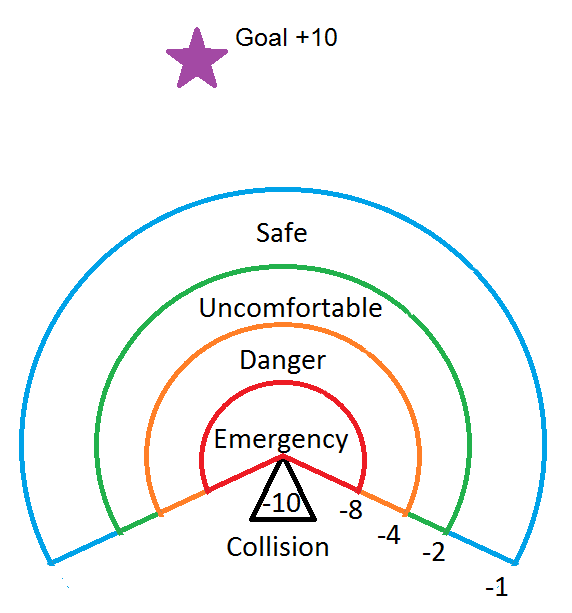
The closer a car gets to the agent the more punishment it recieves. Only a collision will cause the run to end (this is know as a terminal state
This setup is fundamentally floored. Consider the two frames below. The agent has no way to determine whether a collision is imminent, or a car is safely passing.
My next iteration I considered a large reward (+10) was awarded for reaching the right hand side of the screen. This caused some problems during training. Firstly, the agent has no way of telling the difference between;
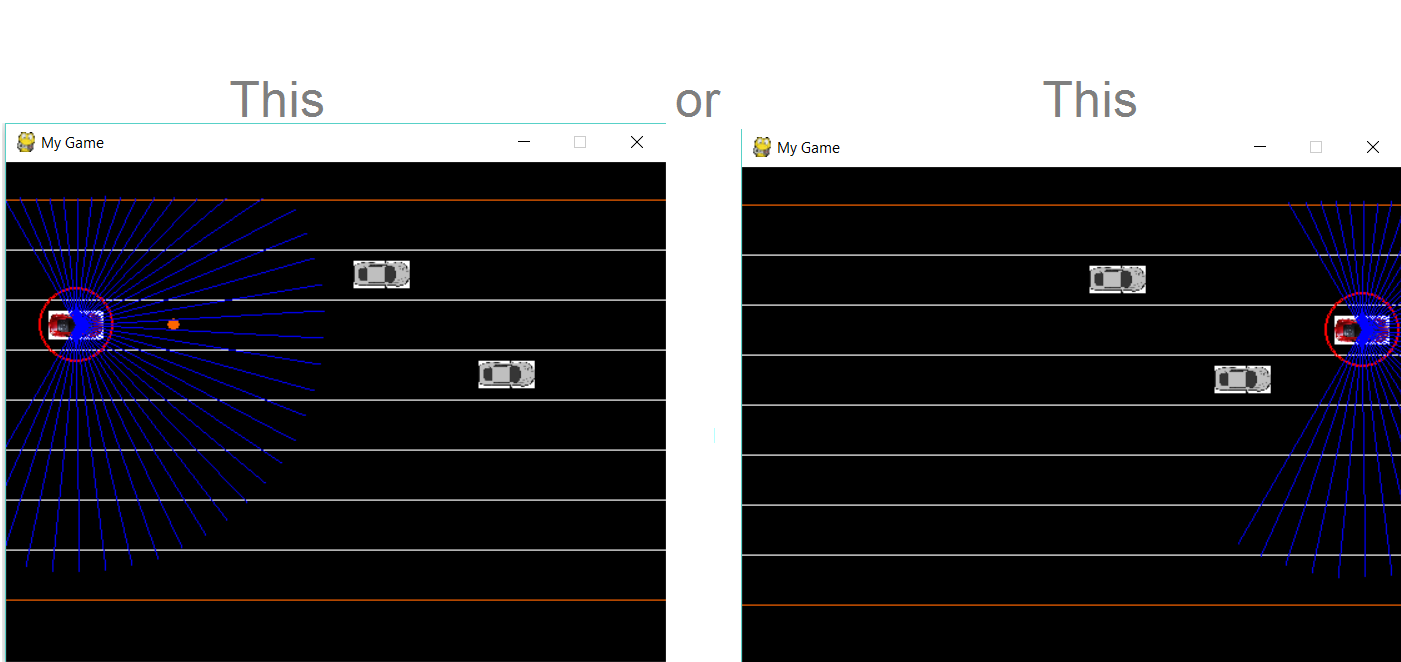
Notice the LiDAR data would be identical for each frame. However, the rewards received are totally different. In the left frame no collision is detected so a reward of +1 would be received. In the right frame, a reward of +10 would be received for reaching the end of the window
The next issue is data normalization. From my readings and suggestions for people much more experienced than myself, keeping input data between values -2 and 2 aids in the training process. I believe this is due to the problem of vanishing gradients among other things.
After several iterations and some advise from people more knowledgeable than me (thanks Siraj), I adopted a +-1 reward system. Each frame the agent is awarded a maximum of +1 if no collision is detected. In an effort to encourage the agent to observe the speed limit the +1 reward for not crashing is multiplied by the factor below. This factor decreases the reward as the agents velocity diverges from a predetermined speed limit.
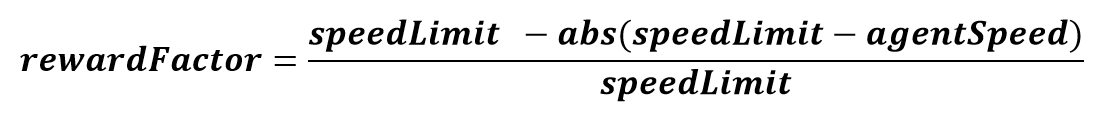
Reward formula
A terminal state occurs if a collision is detected, resulting in a reward of -1 and the simulation is reset. Additionally, when the agent reaches the right hand side of the screen the simulation is reset, but with no penalty.
My First Deep Q-Net
At long last here we are. To minimise clutter and avoid confusion the gist below is just a portion of the main program. For the full program you can clone it from my git repo. Some additions I have omitted are:
- Plotting LiDAR data using matplotlib
- Dynamically varying epsilon
- Toggling learning and display modes, allowing me to stop *learning *and use the Q-Net at the stage it is up to during training
- Various debugging print statements
Q-Net Architecture
As with the reward system, the CNN architecture went through several iterations. I ended up settling on a reduced version of the CNN used by Deep Mind in Mnih et al).
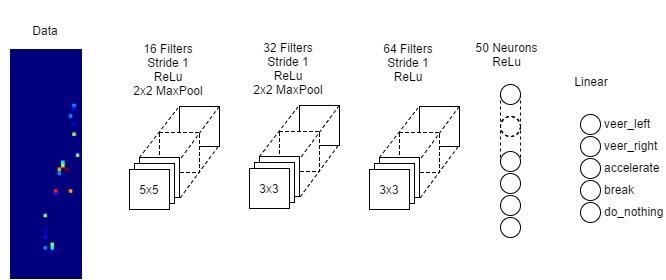
Model architecture
Iteration 1: Learning To Do Nothing
The first iteration the agent is initialised in the same location at a set velocity. There are 2 static obstacles that are initialised out of the path of the agent. All the agent needs to learn is to select the do_nothing action every frame. Below is a video of the agent towards the end of training, once I was happy it was learning I pulled the pin and began iteration 2. This is after about 200,000 frames of training, 50,000 frames in the replay buffer and a batch size of 30.
Iteration 2: Static Obstacle Avoidance
The next iteration does what it says in the box. Two statics obstacles initialised in the same positions each epoch. One of the obstacles is initialised in the path of the agent. The agent is still initialised in the same location each epoch. This is after about 500,000 frames of training, 50,000 frames in the replay buffer and a batch size of 30.
Iteration 3: Static And Random
This is where I’m up to at the moment. Still static obstacles, but totally randomized. I have just gone back to uni for the semester. So I’m not sure how much time I’m going to have to continue working on this, but I will be working on it in some capacity.
I have recently been working on a simulation using the Unity game engine. I cannot overstate how much I regret not doing this sooner. The simulation runs smoother with more LiDAR beams, physics is built in, its easier to program. Literally everything is better. I’ll add updated simulation code and GitHub links as I complete them.
I have not yet completed the final iterations. I am not sure how long it will be before I get back to this project as I am now in my final year of my degree so I’m pretty busy. The next step is definitely going to be moving the simulation into Unity. After that I’ll probably need to through some more powerful GPU time at the problem. Training time was a major issue during this research.
ToDo - Iteration 4: Dynamic And Random 2 Obstacles
ToDo - Iteration 5: Dynamic And Random 0–10 Obstacles
Looking To The Future
While developing this I have come across a few thing and had some ideas I would like to try.
Additional Data
There is some additional data I think will make the agent perform better. By inserting a smaller fully connect neural net that links in with the fully connected layer of the existing Q-Net I intend to provide some useful information to allow the Q-Net to perform more reliably and robustly.
As the sim stands, the agent must infer all its information from the 4 frames of LiDAR data processed through the Q-Net. This poses a problem, inferring speed from the LiDAR data only results in relative speed, not absolute speed. Heading also has a similar problem, both can be easily inserted into the Q-Net.
ToDo - Recursion
The agent has no way of knowing what action it just took. This is partly the reason the actions veer_left *and *veer_right do not change lanes in one go. The Q-Net tended to give the same action multiple times in a row causing it to cross several lanes very quickly. I suspect, this was partly because the time it took the data to reflect any noticeable change caused by the action was around 3–5 frames. In that time, the Q-Net had performed the same action again and again. By feeding the past actions back into the Q-Net I may be able to get a more robust performance.
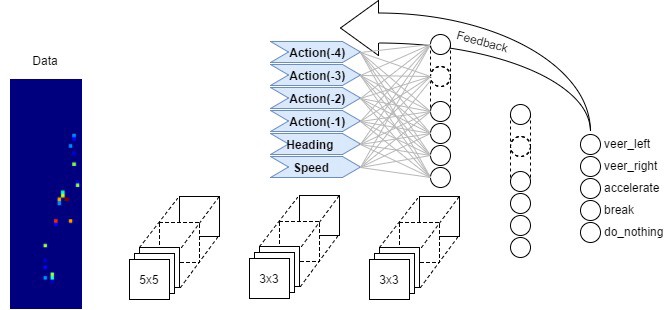
An idea to add additional inputs to the Q-Net, including recursively feeding back previous actions. **Upon editing this 3 years later (atm 2020) I realise this is a bit naive, but considering this was my first attempt at Deep Learning at all this is not a bad idea. These days I'd use an LSTM or something.
Also,this article I linked earlier goes over Splitting Value and Advantage and Double DQN. I definitely want implement these modifications at some point. I just need the time, I plan to work on it over the winder and summer breaks this year. Ideally I will be able to incorporate it into my final year project. Either way, I’ve been bitten by the blogging bug so I’ll post whatever I end up doing.

{kind=link}